Building Robust Signup Systems with Deduplication Logic
Keeping your signup system clean sounds simple… until real users start interacting with it. People sign up twice, use different emails, forget they already registered, or submit information on behalf of someone else who’s already in your system. Before you know it, you’re dealing with duplicate records, confused users, and messy data that’s hard to trust.
This article breaks down how to build a signup flow that quietly handles all of this behind the scenes. No drama for the user, no clutter in your database. Just practical strategies, real-world examples, and the logic you need to keep your registration data clean from day one. We’ll start with the most simple solution and gradually make it complex and robust. Lets dive in.
1. Email / Phone Number Uniqueness
This is as simple as can be and what most tutorial videos teach. The email (or phone number) must be unique per user. For our hypothetical system, two users might submit the same phone number (eg. a parent using their phone number for their underage child) but emails must be unique. Simply put, no two users can have the same email — easy peasy.
During sign up, the new user enters their name, email and phone number and the backend service simply checks the database — “Is there any other user using this email?” If yes, reject the new registration. If no, create the account for the user. That’s all ;)

Email / Phone Number Uniqueness
2. Fuzzy Matching & Using Weights
Relying only on email for uniqueness has a hidden flaw: many people use more than one email address. So even if your database shows 100 user accounts, the real number might be closer to 74 because some individuals registered multiple times with different emails.
In some applications this is harmless. In others, it creates confusion, breaks reporting, or even affects compliance. When accuracy matters, you need stronger guarantees of uniqueness than email alone can provide.
A practical case where stricter uniqueness checks matter is when users can register / submit information for other people in the system.
Imagine a household: Richard and Cynthia are married, and they both use your application independently. One day, Richard logs in and submits an application for their daughter, Martha. A few days later, Cynthia logs in and submits the same information for Martha again.
Without a strong deduplication check — based on identifiers like full name, phone number and date of birth— the system would treat these as two separate submissions. With proper safeguards, the second submission should be flagged as a potential duplicate so the team can review instead of accidentally creating two records for the same person.
Our updated system design introduces a deduplication algorithm (I’ll break down how it works shortly). When a new registration comes in, the algorithm compares it against existing records and computes a similarity score for each potential match. It then returns the highest score to the service layer, which applies a predefined threshold to decide whether the incoming record should be created immediately or flagged for manual review.
However, “basic checks” like email and ID number uniqueness are still enforced and is the first layer. If either email or ID number uniqueness fails, the service rejects the registration outright. If not, as the second layer, the deduplication algorithm is used.
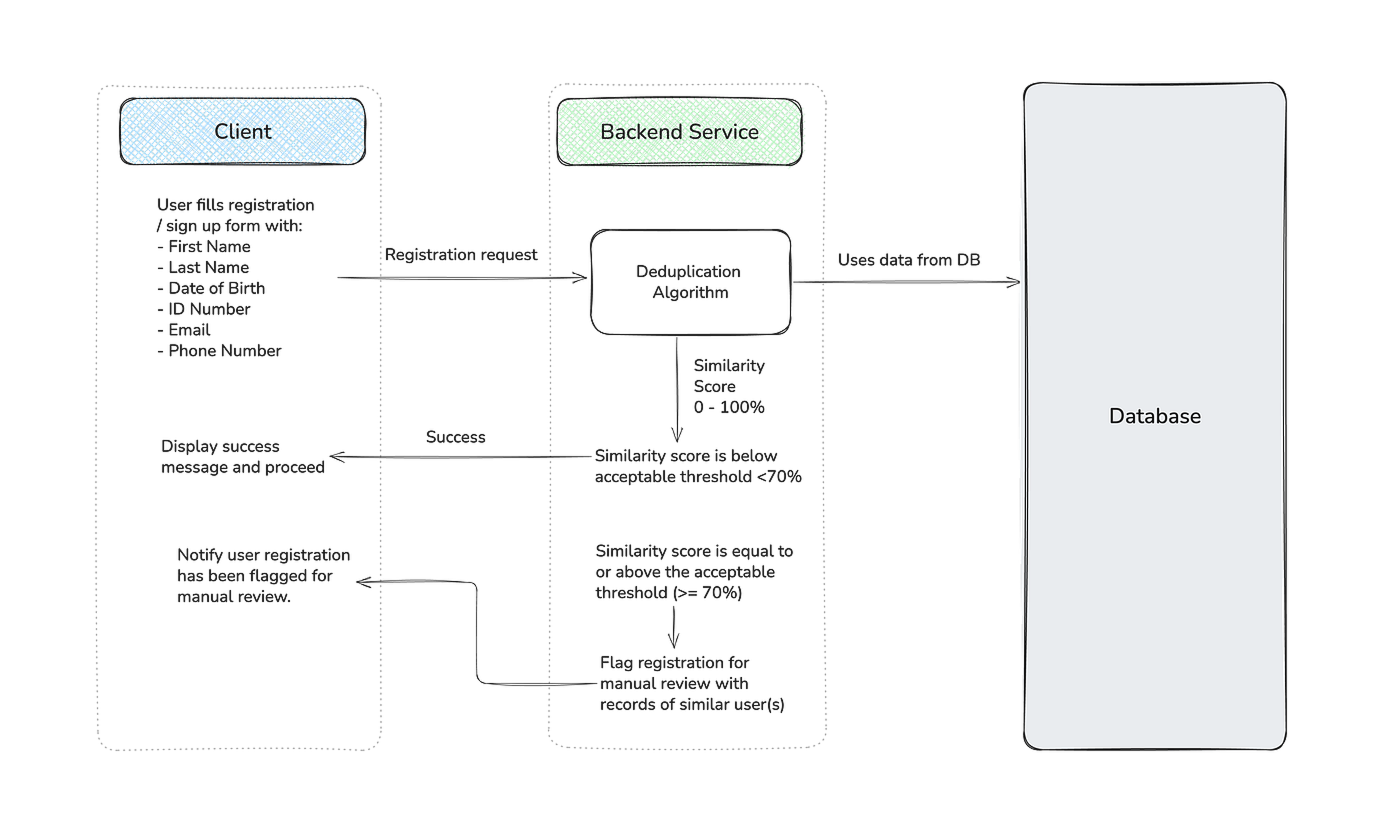
Fuzzy Matching & Using Weights System Design
Lets explore the Deduplication Algorithm used in the system design above.
The algorithm is to account for several potential duplication cases that might arise. The output is a single similarity score so that the service layer can decide to flag for review or create the account. Some cases that it considers includes:
- Two people with same date of birth, different phone numbers and different first and last names.
- Three people with different date of births, same first name but different last names.
- Two people with a slightly different first name (eg. Micheal and Michael) — notice the “ea” and “ae” ? , same last name and same date of birth
….and so on and so forth. There are so many permutations.
Our algorithm works with these data points in determining a potential duplication:
- First name, middle name and surname
- Date of Birth
- Phone Number
Steps of the algorithm:
- Fetch all potential matches from the database
For the incoming registration, check for any records that have a similar phone number or date of birth and names.
// Pseudocode: fetch possible duplicates
const potentialMatches = db.user.findMany(
{ where: { OR: [ { phoneNumber: input.phoneNumber },
{ dateOfBirth: input.dateOfBirth },
{ AND: [ { firstName: contains(input.firstName) },
{ lastName: contains(input.lastName) },
{ middleName: contains(input.middleName)
}]} ]}});
- Check length of potential matches array
If the potential matches array is empty, return a similarity score of 0.
if (potentialMatches.length === 0) { return { isDuplicate: false, score: 0 }; }
- Calculate similarity score for all potential matches
Each data point is assigned a weight that I calibrated through trial and error to reflect its relative importance. The name carries the highest weight, followed by date of birth, and then phone number, corresponding to how relevant each is in identifying duplicates.
| Data Point | Raw Weight | Normalized (0–100%) |
|---|---|---|
| Name similarity | 0.5 | 50% |
| Date of birth | 0.3 | 30% |
| Phone number | 0.2 | 20% |
We’re utilising the fuzzball package to compare names. You can read more about fuzzy matching here. Our acceptable threshold is 70% or 0.7.
let maxScore = 0;
for (const user of potentialMatches) {let score = 0;
// Name similarity (0–1), weighted at 50%const rawNameSimilarity = (fuzz(firstName, user.firstName) +fuzz(middleName, user.middleName) +fuzz(lastName, user.lastName)) / 300;
const nameScore = rawNameSimilarity * 0.5; // 50%
// Date of birth exact match → 30%const dobScore = isSameDate(user.dateOfBirth, dateOfBirth) ? 0.3 : 0;
// Phone match → 20%const phoneScore = user.phoneNumber === phoneNumber ? 0.2 : 0;
// Total score (max 1.0)score = nameScore + dobScore + phoneScore;
// Threshold for manual reviewif (score >= 0.7) {potentialMatchesForReview.push(user.id);}
maxScore = Math.max(maxScore, score);
return {isDuplicate: maxScore > 0.7,score: maxScore,potentialMatchesForReview}}
- The service layer actions the incoming registration based on the similarity score returned
In this implementation, when the score is greater or equal to 0.7, it’s flagged for manual review by a human (along with all the potential matches identified).
If the similarity score is less than 0.7, the user account is created
3. ML-Enhanced Deduplication
With the rise of AI and ML, some machine learning models can be employed in deduplication.
A simple random forest machine learning model works well since deduplication is structured and tabular.
The model learns patterns like:
• If names are similar + Date of birth matches → same person.
• If phone numbers match, even if emails differ → same person.
• If only one field matches → probably different people.
In another article, we’ll explore more about ML-Enhanced Deduplication.
Cheers! Let’s build robust systems! The algorithm presented here might have some flaws or edge cases I didn’t consider, feel free to point them out in the comments!
